Upstash Embedding Models - Video Guide
Let’s look at how Upstash embeddings work, how the models we offer compare, and which model is best for your use case.Models
Upstash Vector comes with a variety of embedding models that score well in the MTEB leaderboard, a benchmark for measuring the performance of embedding models. They support use cases such as classification, clustering, or retrieval. You can choose the following general purpose models:The sequence length is not a hard limit. Models truncate the input
appropriately when given a raw text data that would result in more tokens than
the given sequence length. However, we recommend using appropriate models and
not exceeding their sequence length to have more accurate results.
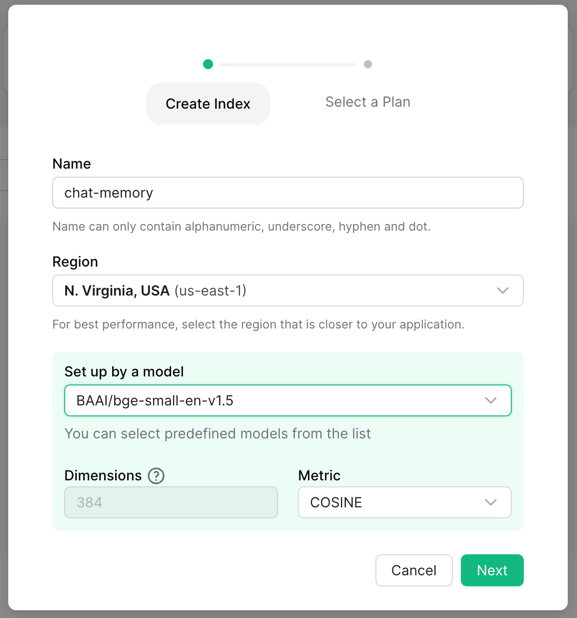
Using a Model
To start using embedding models, create the index with a model of your choice.