Get Started
Create a Kafka Cluster
If you do not have a Kafka cluster and/or topic already, follow these
steps to create one.
Prepare the Amazon S3 Environment
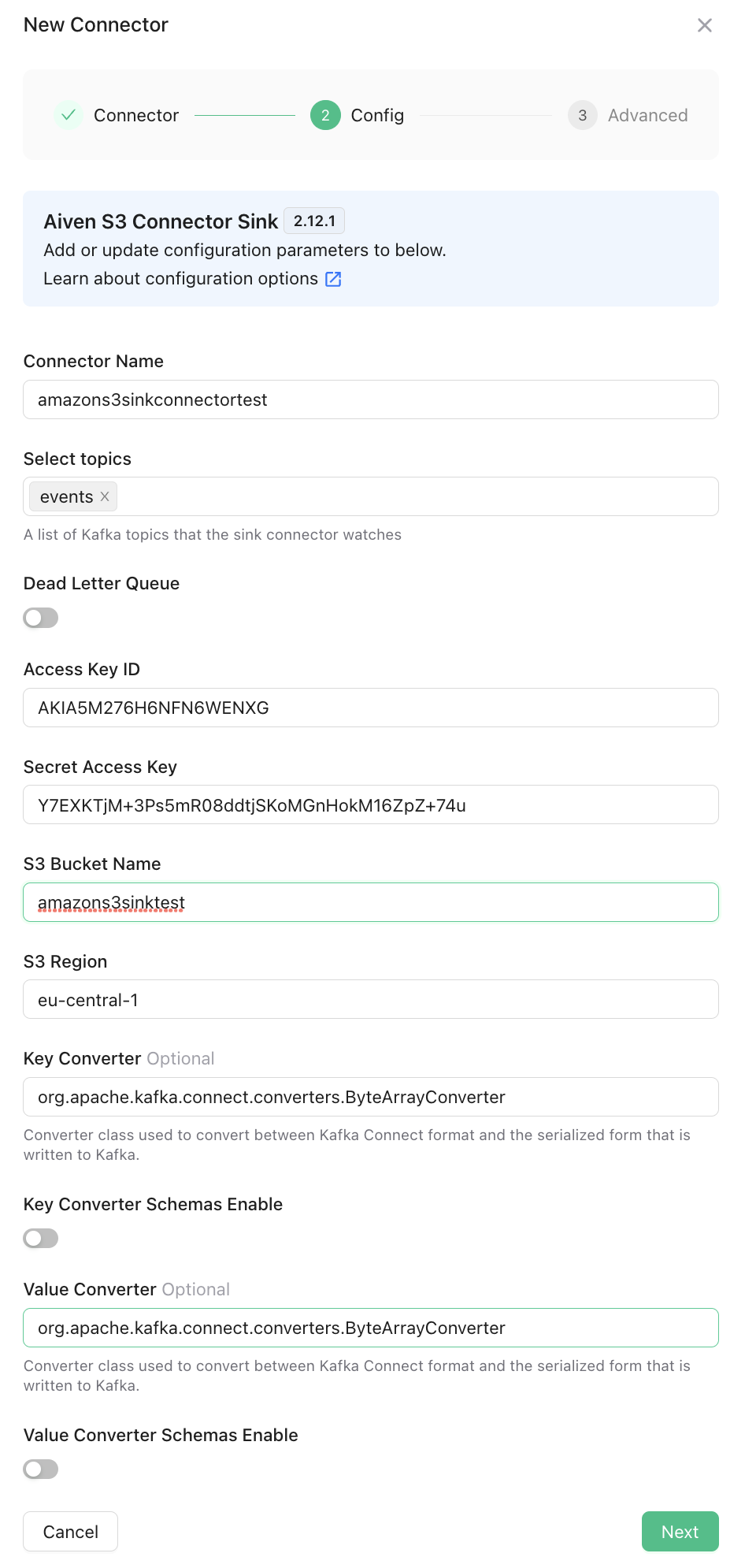
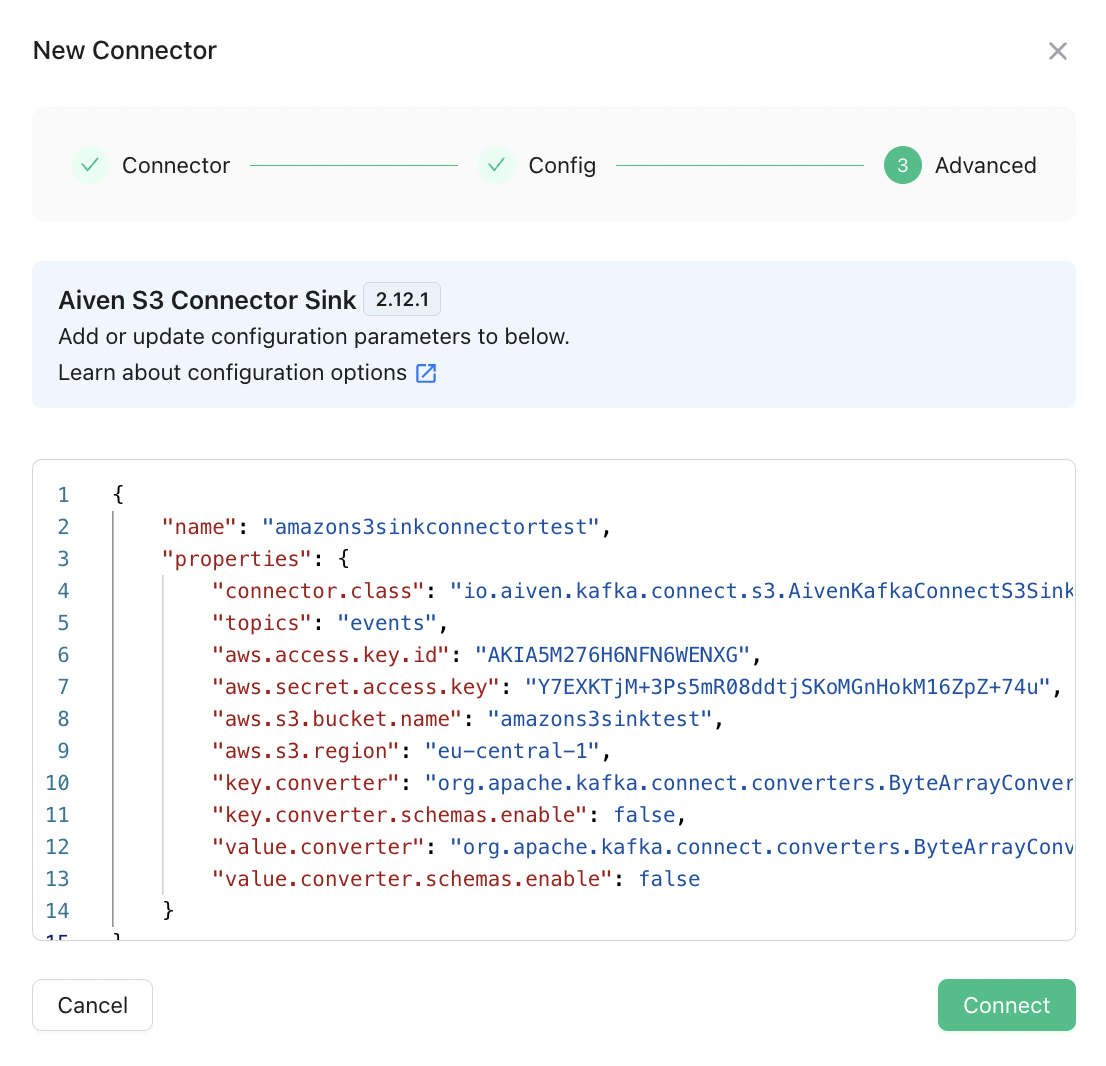
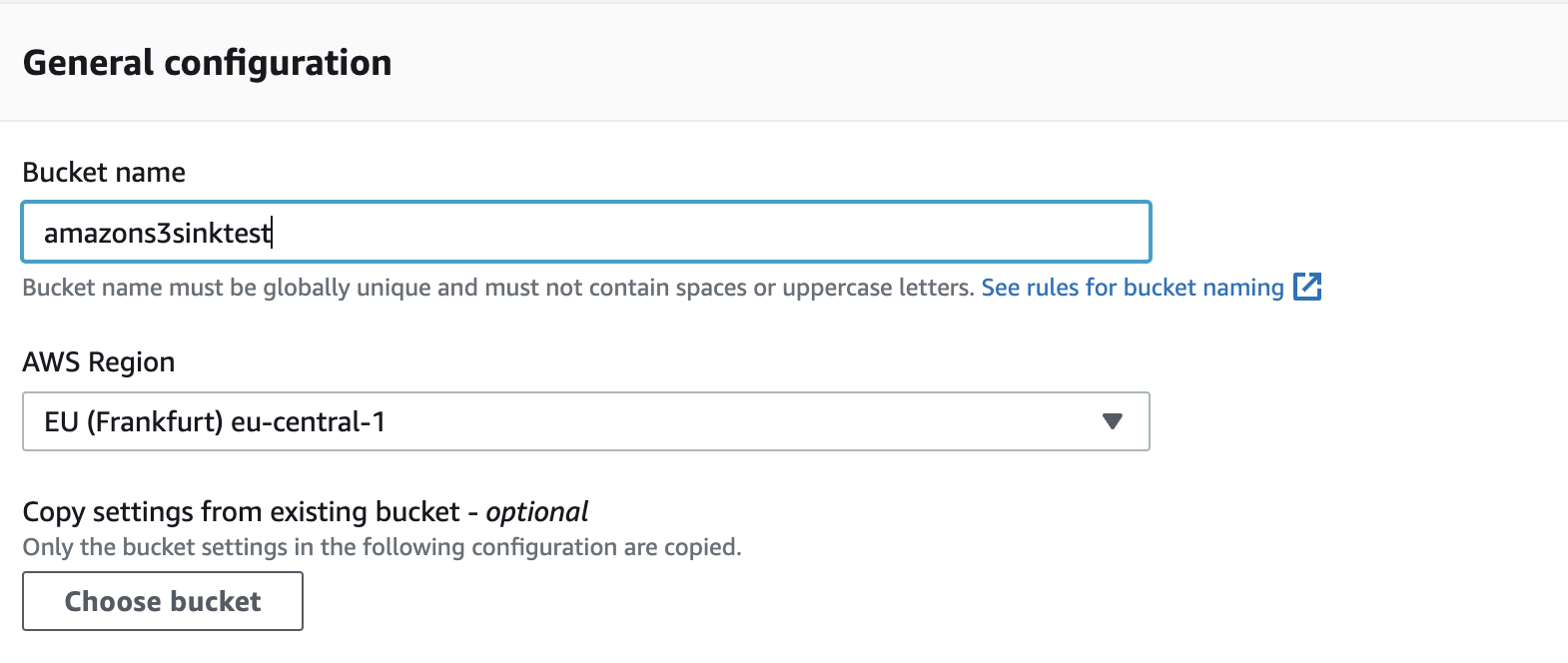
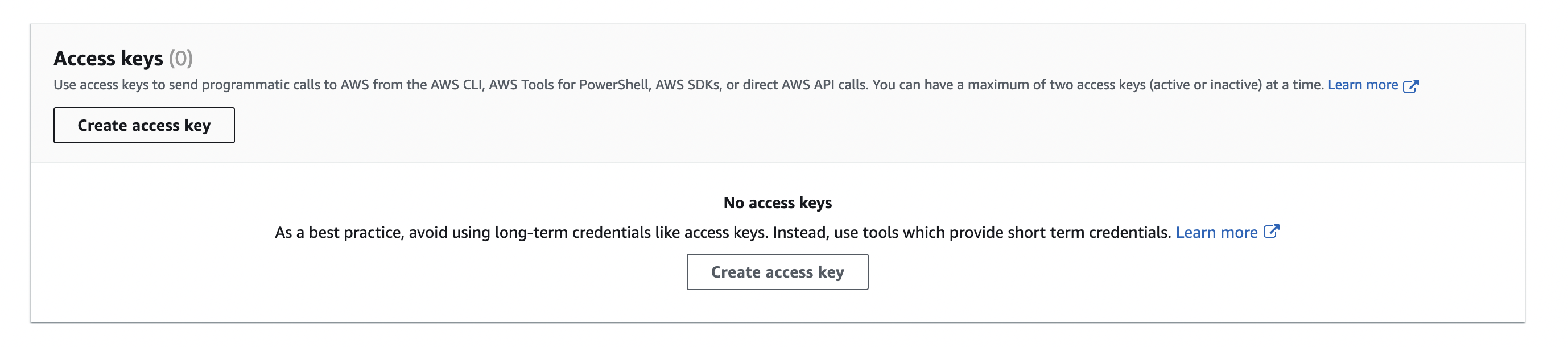
If you already have a Amazon S3 environment with the following information, skip this step and continue from the Create The Connector section. Note that the user with the given access keys, should have permission to modify the given bucket.aws.access.key.idaws.secret.access.keyaws.s3.bucket.nameaws.s3.region

Create the Connector
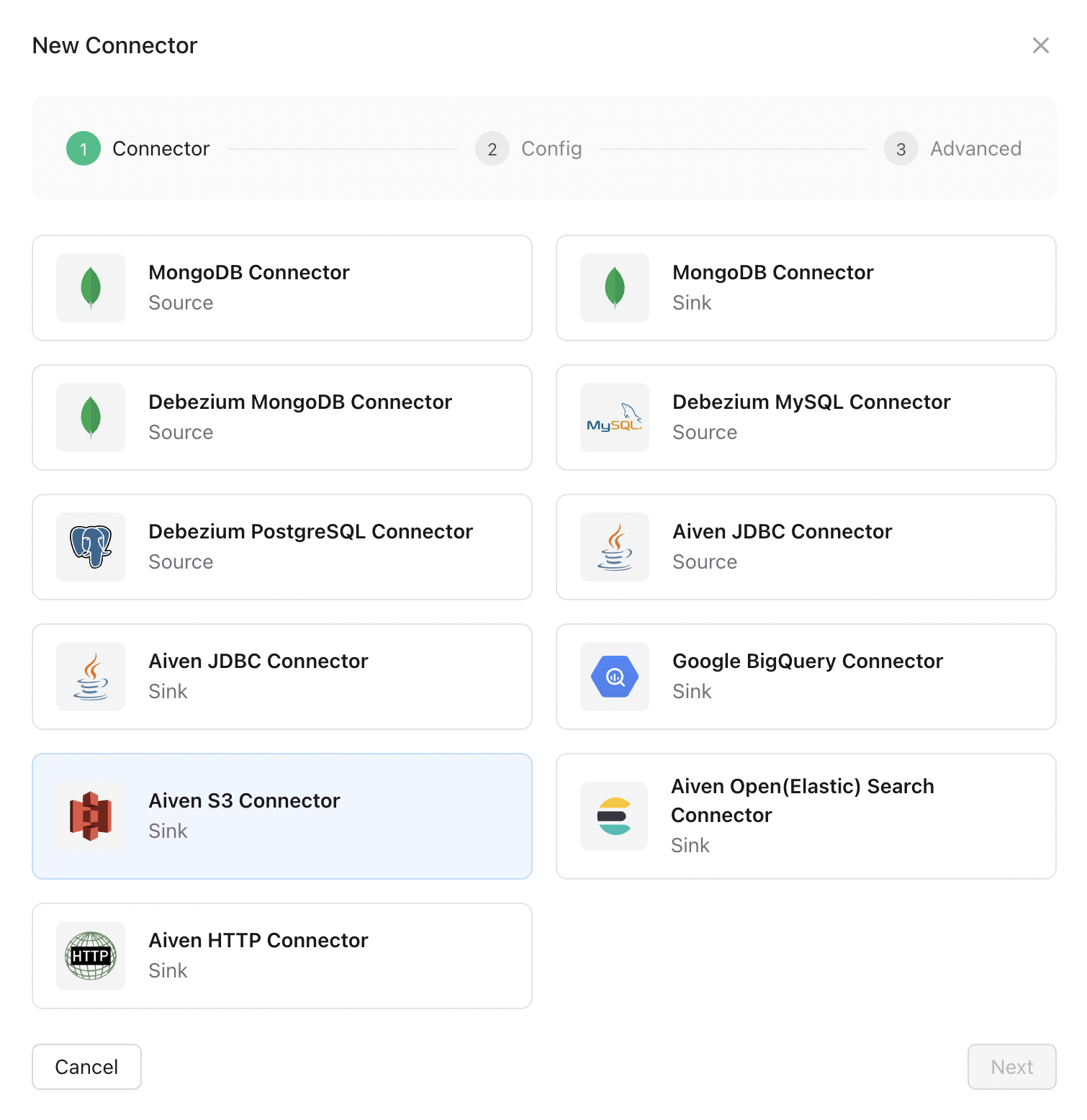
Go to the Connectors tab, and create your first connector by clicking the New Connector button.